
Банк — это по определению «кредитно-денежная организация», и от того, насколько успешно эта организация выдает и возвращает кредиты, зависит ее будущее. Чтобы успешно работать с кредитами, нужно понимать финансовое положение заемщиков, в чем помогают факторы кредитного риска (ФКР). Кредитные аналитики выявляют их в огромных массивах банковской информации, обрабатывают эти факторы и прогнозируют дальнейшие изменения. Обычно для этого используется описательная и диагностическая аналитика, но мы решили подключить к работе инструменты машинного обучения.

Некоторые факторы кредитного риска лежат на поверхности, другие нужно искать глубоко в недрах банковских данных. Изменения курса доллара, выручки клиента, долговой нагрузки, падение продаж и рейтингов, суды, уголовные дела, слияния и поглощения — все это дает статистический сигнал разной силы. Чтобы правильно составить общую картину по заемщику, необходимо не только уловить все связанные с ним сигналы, но и оценить их силу.
В работе с ФКР описательная и диагностическая аналитика зарекомендовали себя хорошо, но все-таки эти методы не лишены недостатков. Использование аналитики ограничивается регуляторами — не все продвинутые методы и модели могут быть одобрены с их стороны. Аналитика не отличается гибкостью и не дает возможности представить данные в произвольном срезе — а это часто бывает очень нужно. Да и с оперативностью в данном случае не все здорово. А еще случается, что для работы каких-то аналитических моделей просто не хватает данных.
Почему бы не попробовать для этих целей машинное обучение? Так вполне можно улучшить расчет значимости факторов кредитного риска, говоря техническим языком — повысить на несколько процентных пунктов показатель Джини (Gini), по которому мы оцениваем точность прогнозных моделей. Чем лучше расчет ФКР, точнее оценка финансового состояния клиентов — тем выше качество кредитного портфеля банка. И тем ниже доля ручного труда.
Ход проекта
Для хранения больших данных выбрали Cloudera Hadoop, для доступа к сырым данным развернули Apache Spark и Apache Hive SQL, для координации и запуска потоков загрузки и расчета данных — Apache Oozie. С помощью Apache Zeppelin и JupyterHub визуализировали и исследовали данные. Помимо этого, использовали ряд библиотек машинного обучения, поддерживающих параллельную обработку — Spark MLIB, PySpark и H20.
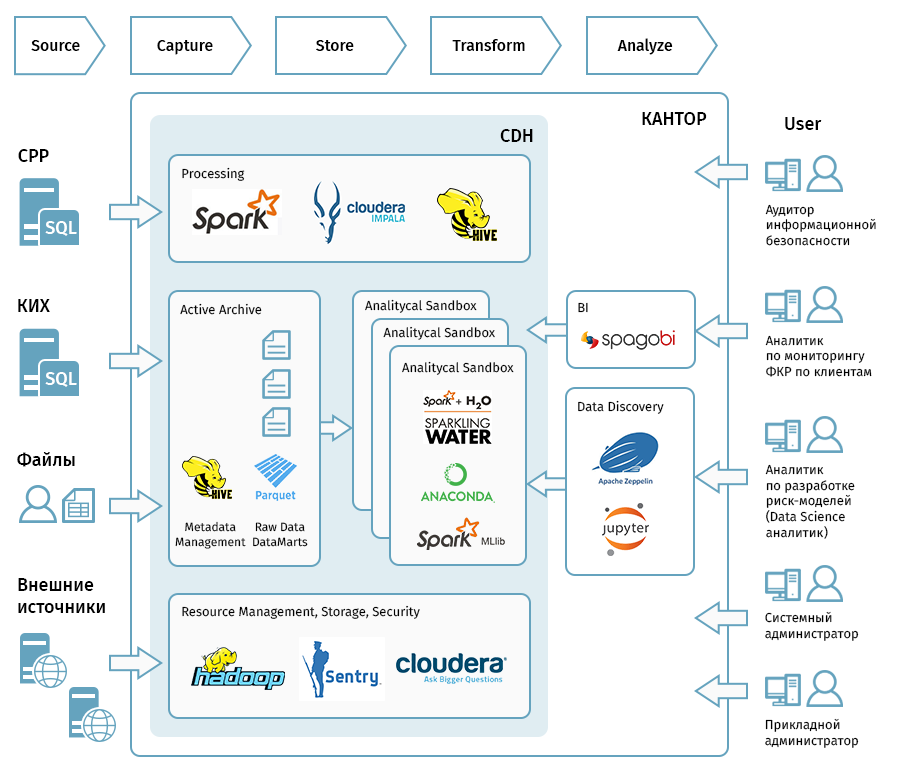
На все это выделили семь узлов:
- 3 master-узла с 64 Гб vRAM и 2 Тб дискового пространства у каждого
- 3 data-узла с 512 Гб vRAM и 8 Тб у каждого
- 1 узел для приложений со 128 Гб vRAM, 2,5 Тб
Весь проект занял три месяца и состоял из трех демо-стадий, по четыре недельных спринта в каждой. Для расчета в ходе проекта выбрали 22 фактора кредитного риска.
На первой стадии мы развернули инфраструктуру и подключили первые источники данных:
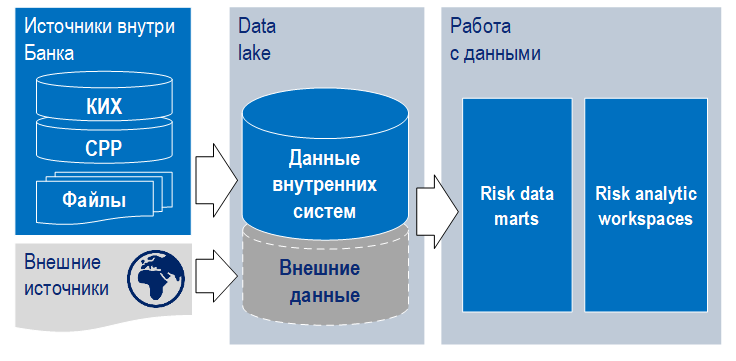
- Корпоративное информационное хранилище (КИХ) – основное хранилище в банке. Чтобы свободно оперировать с данными в пределах Data Lake и не создавать нагрузку на продакшн-системы, мы загрузили его фактически целиком.
- Система расчета рейтингов (СРР) – одна из основных баз данных для оценки рисков, связанных с деятельностью корпоративных клиентов. Содержит информацию о рейтингах предприятий, показатели финансовой отчетности.
- Данные из внешних источников, отражающие аффилированность и другие критерии.
- Отдельные файлы, содержащие дополнительную информацию и данные для работы дата-сайентистов.
На второй стадии рассчитали первые ФКР, попробовали построить модели на основе этих показателей, установили BI-средство и обсудили как визуализировать динамику ФКР. В итоге решили сохранить привычную для пользователей структуру таблиц Excel в новом инструменте, оставив продвинутую визуализацию на будущее.
И наконец, на завершающей стадии мы загрузили все недостающие данные, в том числе из внешнего источника. В банке опасались, что их статистическая значимость будет невелика, так что мы провели статистические тесты, которые доказали обратное. В итоговом демо продемонстрировали работу datascience-инструментов, BI, регулярную загрузку и обновление данных. Из 22 факторов в рамках пилота не рассчитали только два, из-за внешних причин — отсутствия данных необходимого качества.
Результат
Кластер на Hadoop легко масштабируется и позволяет скармливать моделям больше данных, а они могут выполнять вычисления параллельно. Показатель Джини вырос — модели стали точнее предсказывать те или иные события, связанные с факторами кредитного риска.
Нашим аналитикам раньше приходилось обращаться в Департамент ИТ, чтобы мы написали SQL-запросы к корпоративному хранилищу, а потом обрабатывать модели на своих персональных компьютерах. А теперь пилотный кластер позволяет аналитикам писать запросы самостоятельно, то есть поднимать сырые данные и обрабатывать модели получается гораздо быстрее.
Планы
В этом году мы продолжим развитие проекта. Развернем инфраструктуру Data Lake на специализированном оборудовании, чтобы повысить скорость выборки и обработки. Организуем на основе «озера» единый, централизованный ресурс для кредитной аналитики. Добавим еще несколько источников данных и подключим новые библиотеки машинного обучения.
Нашим проектом заинтересовались другие подразделения банка — CRM, внутренний аудит (поиск мошенников, выявление сомнительных операций), операционная поддержка (антифрод), отраслевые аналитики. Когда с помощью «песочницы» мы предоставим им наши разработки, они получат легкий доступ к данным, возможность подключать любые источники данных и экспериментировать на них с помощью моделей машинного обучения.

