
В прошлом примере мы занимались поддержкой воображаемой телепортационной корпорации PanContinental. Сегодня придется решать новые задачи. Но если ранее мы справились с проблемой буфера обмена виртуальной машины, когда у пользователя не работала функция «копировать/вставить», то сегодняшняя задача будет несколько сложнее.
Один из сотрудников нашей выдуманной компании PanContinental создал заявку с высоким уровнем приоритета, комментируя, что не может оформить вэйпоинт (waypoint) при указании точки назначения для телепортации. Эта операция заканчивается неудачей. Из-за невозможности зарегистрировать вэйпоинт одного клиента тормозится процесс для всех остальных. Возникает очередь из заявок на телепортацию большого количества пользователей. Это, как полагает сотрудник, происходит из-за низкой производительности виртуальной машины, которая в силу загруженности не справляется с обработкой запросов. Наша задача – в короткие сроки решить озвученную проблему.
Методология устранения неисправностей
Прежде чем переходить к решению задачи, убедитесь в достоверности проблемы. А после проработайте возможные варианты и пути решения. Но для начала вспомним о методологии устранения неисправностей. Выявление симптомов – первый шаг на пути к победе. Прежде чем понять, в чем дело, необходимо выяснить, что конкретно вызывает текущую проблему.
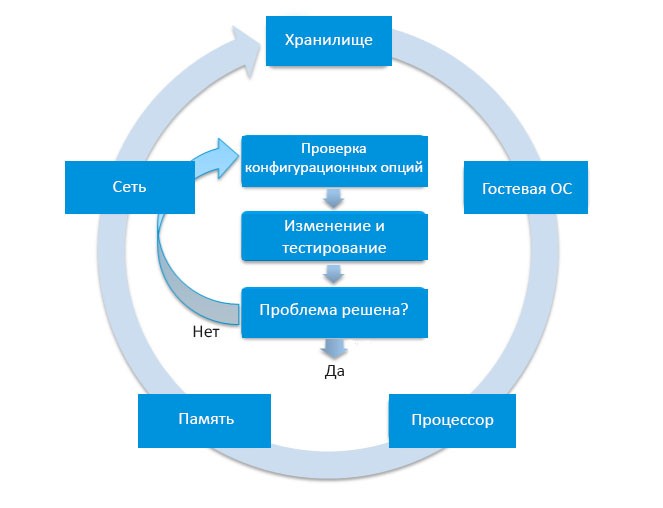
Иллюстрация методологии устранения неисправностей
Заметка! Помните, что не все правила действенны и применимы к вашей ситуации. Имейте в виду и тот факт, что из целого списка подсистем какая-то одна может стать причиной проблемы. На диаграмме (см. рисунок выше) представлены подсистемы, работоспособность которых необходимо проанализировать.
На что обратить внимание? По статистике, наиболее часто проблемы с производительностью вызывает дисковая подсистема. В то время как сеть вызывает подобное значительно реже. Обращайте внимание на каждую из подсистем, проводите анализ работоспособности, выявляйте узкие места и составляйте список вариантов их устранения. Прорабатывайте каждый из способов решения, проводите тестирование и сравнивайте результаты до и после. Если проблема так и не устранилась, пробуйте другие методы.
Сбор статистики и анализ производительности
Итак, для начала подключимся к виртуальной машине (ВМ) пользователя, на которой наблюдается проблема. Для этого используем терминальный доступ. Отметим, что на ВМ пользователя уже установлены инструменты, собирающие статистику производительности в реальный момент времени.

Real-time статистика
Таким образом, на рабочем столе ВМ отображается информация об имени хоста, IP-адресе, загрузке CPU и оперативной памяти. График отображает общий уровень загрузки (Total) и загрузку на уровне ядра гостевой ОС (Krnl).
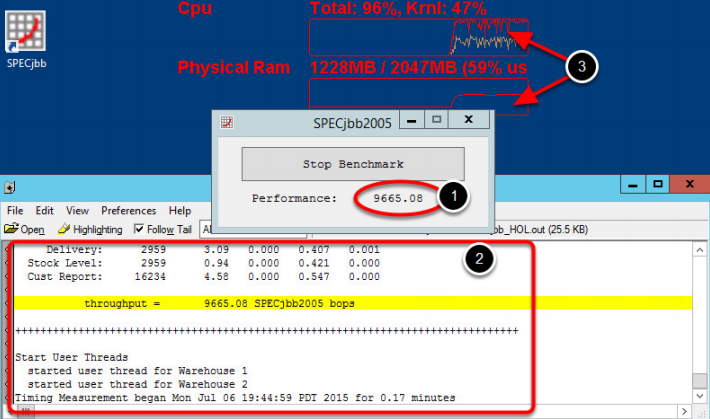
Кроме того, в сценарии используется инструмент SPECjbb – что-то вроде эталонного теста, созданного корпорацией Standard Performance Evaluation (SPEC) для измерения производительности. Чтобы запустить тест, кликаем по ярлыку SPECjbb, расположенному на рабочем столе виртуальной машины. Инструмент позволяет измерить производительность CPU и Memory. Для старта теста нажимаем кнопку Start Benchmark.
Сравнение результатов производительности
Текстовый файл, расположенный ниже, отражает собранную статистику. Результаты, интерпретируемые как количество бизнес-операций в секунду (BOOPS), подсвечиваются желтым цветом. Если закрыть окно SPECjbb или нажать кнопку Stop Benchmark, сбор статистики прекратится. Обратите внимание, что результаты здесь обновляются каждые 10 секунд. Если вы запустили SPECjbb в первый раз или внесли изменения в инфраструктуру, следует подождать выполнения нескольких циклов тестирования. Тогда результаты будут максимально точными и приближенными к реальности. Но поскольку SPECjbb все же создает определенную нагрузку на инфраструктуру, этот инструмент не рекомендуют использовать в производственной среде. Лучше обратить внимание на решение vRealize Operations Manager, созданное для мониторинга производительности в условиях рабочего процесса.
Теперь предлагаем вернуться к показателям SPECjbb. Полученные результаты на рисунке выше свидетельствуют о низкой производительности perf-01. А как мы помним, согласно сценарию, эта ВМ отвечает за обработку запросов телепортации для клиентов компании PanContinental. Повторимся, что в результате низкой производительности возникают проблемы с обработкой запросов, а значит, становится невозможным оказание услуг компании. Наша задача – увеличить производительность виртуальной машины.
Итак, завершаем терминальную сессию и обращаемся к веб-консоли vSphere Web Client. После успешной аутентификации переходим в закладку Home -> Hosts and Clusters.
Консоль управления vSphere Web Client
Подключаемся к vCenter и хосту, где расположена виртуальная машина perf-01a.
Обзор свойств виртуальной машины
К слову сказать, используя vSphere performance charts, вы можете просматривать статистику производительности ВМ в real time, а также собирать статистику по дата-центру, кластеру, пулу ресурсов или ESXi-хостам. Для отображения деталей на уровне отдельно взятой виртуальной машины выбираем perf-01a и переходим в закладку Monitor -> Performance. Здесь можно посмотреть на общую и расширенную картинку производительности (Overview и Advanced). Для большей детализации переходим в раздел Advanced. По умолчанию значения здесь обновляются каждые 20 секунд.
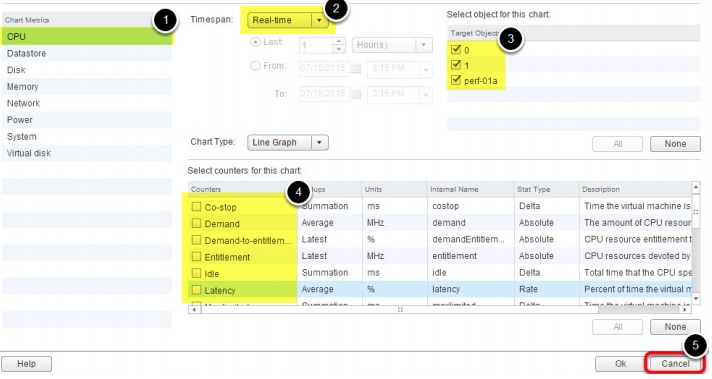
Настройка дополнительных опций
Здесь можно указать объект производительности, определить временной интервал и тип метрики для каждого объекта. В нашем примере «0» указывает на первый vCPU виртуальной машины, «1» определяет второй vCPU, а «perf-01a» оба vCPU. Обратите внимание, что, если в инфраструктуру вносятся изменения для точного отображения результатов, необходимо подождать 30–60 секунд. Real time статистика и здесь фиксирует проблему с чрезмерной загрузкой CPU.
Возможные варианты решения проблемы
Как и в реальной жизни, решить одну проблему, как правило, можно несколькими способами. В нашем случае проблема с производительностью возникает из-за чрезмерного использования CPU. Дело в том, что помимо ВМ perf-01a на хосте esx-01a (с 2-ядерным CPU) расположена еще одна виртуалка perf-02a. При этом perf-01a использует 2vCPU, а perf-02a – 1vCPU. В сумме это составляет 3vCPU.
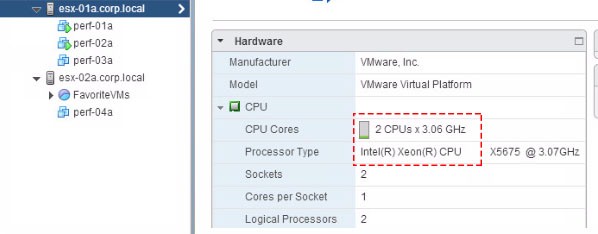
Свойства ESX-хоста
Следовательно, процессорная подсистема используется под завязку и на все 100 %. Чтобы убедиться в этом альтернативным способом, воспользуйтесь метрикой % Ready. Если показатель превышает 10 %, значит, проблема точно существует. В нашем примере все понятно и без этой метрики. Переходим к рассмотрению вариантов решения проблемы.
- Первый вариант: перенести виртуальную машину perf-01a на менее загруженный ESXi-хост. То есть с esx-01 на esx-02a. Этот узел практически не загружен, здесь размещаются две виртуальные машины, использующие незначительное количество процессорных мощностей.
- Второй вариант: перенести ВМ perf-02a на хост esx-02a и добиться аналогичного результата.
- Третий вариант: воспользоваться перераспределением вычислительных ресурсов для машины perf-02a. Для этого перейдите в раздел Edit Resource Settings виртуальной машины и установите лимит на потребление CPU.
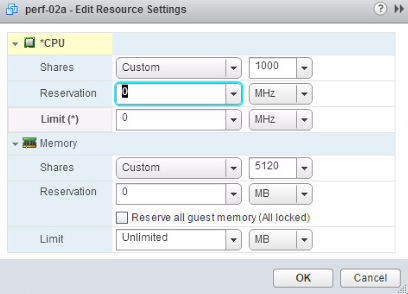
Изменение ресурсных значений
Используйте Resource Allocation для гарантированного предоставления perf-01a необходимого количества процессорных мощностей.
Подводим итоги
В этом практическом кейсе мы рассмотрели несколько вариантов решения проблемы с производительностью ВМ. Не забывайте использовать методику устранения неисправностей и прорабатывать план дальнейших действий. Примеряя выбранное решение к имеющейся проблеме, обязательно тестируйте конечный результат. Главное – добиться поставленной цели.

