

Относительно недавно (3-4 года назад, если не ошибаюсь) производитель отличного сетевого оборудования компания Cisco, начала выводить на корпоративный рынок продукты из других направлений, в том числе и серверного.
Серверное направление у Циски называется — Cisco UCS (Unified Computing System), и представляет собой модельный ряд из «рековых» (rack-mount) и «блейдовых» (blade)серверов.
Рековые сервера объединены в серию «C» а блейды в серию «B». То есть, если сервер называется Cisco UCS C-220-M2 — это стоечный сервер, а если B-220-M2 — это блейд.
Рековые сервера не особо интересные, т.к. не несут в себе ничего необычного, а вот про блейды я бы хотел немного рассказать.
Идеология у данной платформы достаточно интересная. Сами лезвия довольно типичные и мало чем отличаются от лезвий других производителей. Интересные моменты начинаются, когда мы рассмотрим сетевую часть и управление, где Ciscoпредложила очень интересную концепцию.
Да, с рековыми серверами тоже есть инновации в плане сети и управления, но с блейдами это выглядит более эффектно :))
Идея всего этого счастья заключается в «унификации», как можно догадаться из названия 🙂 Под этим наумняченным англицизмом понимается попытка стандартизации однотипных компонентов и консолидации компонентов общего назначения (если вы ничего не поняли — не расстраивайтесь, чуть ниже по тексту вы поймете о чем речь).
Для начала — блейд-система Cisco UCS предполагает использование конвергентной сети на основе 10G Ethernet. Для тех кто не в теме, конвергентная сеть, в данном случае, значит объединение SAN и LAN в одну физическую сеть. Данный подход считается более универсальным и гибким (как говорит «циска» — унифицированным :)) в построении сети, т.к. позволяет использовать единое сетевое оборудование (конвергентрые коммутаторы) для агрегации всех сетевых линков и управления всем сетевым трафиком из единой точки.
То есть, это уже как минимум сокращает количество оборудования, необходимого для построения ЦОД. Вместо двух коммутаторов для LAN и двух коммутаторов для SAN — мы берем два конвергентных коммутатора (например Cisco Nexus 5K серии) и заводим туда SAN и LAN.
Вообще, в основе сетевой подсистемы Cisco UCS лежит так называемая «унифицированная фабрика», но понятие это достаточно абстрактное, поэтому зацикливаться на нем я не буду, а попытаюсь более простым языком обрисовать идею, которую компания Cisco закладывает в сетевую подсистему своих блейдов.
Лучше всего особенности Cisco UCS объяснять в сравнении с обычным подходом blade-систем, поэтому, я так и сделаю.
Возьмем классическую blade-систему…
Как мы знаем, в классическом подходе у нас есть шасси («корзина»), в которой есть сервера. Кроме серверов, в корзине собраны общие компоненты для всех серверов:
— блоки питания
— вентиляторы
— сетевые устройства (коммутаторы или Path through модули)
— система управления
в первую очередь, нас интересуют сетевые устройства и система управления.
В классическом подходе, у нас для каждого протокола свой коммутатор или Path throughмодуль.
То есть, если нам нужно каждому серверу дать 1G Ethernet и 8G FC — мы ставим 2 коммутатора 1G Ethernet и 2 коммутатора 8G FC и получаем у каждого сервера 2 шт.Ethernet карты 1G и 2 карты 8G FC. И условно все… Как-то варьировать сетевые устройства отдельного сервера особо не получится. Конечно, есть вариант поставить еще 2 коммутатора в корзину, но далеко на этом тоже не уедешь, и особого разнообразия не получишь.
Кроме того, каждый коммутатор и порты на нем нужно настраивать и обслуживать отдельно, что в случае с большим количеством корзин — весьма накладно.
Что нам предлагает Cisco UCS:
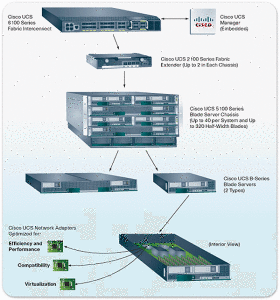
С питанием и охлаждением здесь все то же.
Сетевые функции в Cisco UCS выполняет отдельное устройство — Fabric Interconnect (FIС)

которое выполнено в форм-факторе 1U (32 порта) или 2U (64 порта). Данное устройство выполняет роль конвергентного коммутатора (по сути — это тот же Nexus 5K серии), а также системы управления, о которой мы поговорим позже. Для отказоустойчивости, данных устройств должно быть 2.
Блейд-шасси Cisco UCS:

не содержит сетевых блоков в виде коммутаторов и Path through модулей, заточенных под конкретные задачи. Вместо них, в корзине установлены 2 стандартных (унифицированных :))) модуля ввода-вывода (Fabric Extender),

каждый из которых имеет 4 или 8 портов 10G. Fabric Extender называются унифицированными неспроста, т.к. способны передавать трафик по любым протоколам (Ethernet, Fibre Channel, FCoE).
Каждая корзина, посредством данных модулей ввода-вывода, подключается к Fabric Interconnect с помощью до 16 медных 10G шнурков (по 8 шт. на каждую FIC), что обеспечивает пропускную способность до 160 Гбит/сек между шасси и фабрикой.
За счет того, что сетевые коммутаторы вынесены за пределы шасси и являются общими для нескольких шасси (до 40 шт.), а само шасси высотой 6 юнитов, достигается достаточно высокая (хотя и не самая высокая) плотность системы по ресурсам, в пересчете на занимаемые в шкафу юниты. Кроме того, упрощается коммутация, настройка и обслуживание, масштабирование, высокая гибкость конфигурации, появляется единая точка управления всем этим хозяйством и т.п..
Пример коммутации Cisco UCS:
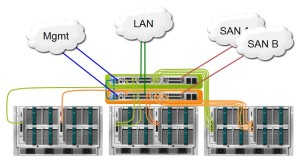
В другом ракурсе:

Конечно, в случае когда у нас всего одно шасси, чисто архитектурно — классическая схема будет проще, потому что у нас все в одной корзине и не нужно какие-то 2 дополнительные устройства ставить сверху.
В случае, когда у нас есть 2 и больше шасси — концепция Cisco UCS имеет явные преимущества, особенно, если учесть мощную систему управления.
К стати о системе управления.
Как я уже и говорил, все управление Cisco UCS сосредоточено на Fabric Interconnect. Система управления называется Cisco UCS Manager и имеет графический интерфейс иCLI. Графическая оболочка традиционно выполнена на яве (гори она в аду) а CLIдоступен через консольный порт на самой железке, или по SSH.
UCS Manager


позволяет централизованно управлять всей системой UCS, которая может содержать до 40 шасси и до 320 blade-серверов (возможно уже больше, могу ошибаться), при чем управлять достаточно гибко и эффективно.
Что я подразумеваю под гибкостью? Это в первую очередь виртуализация (если можно это так назвать) ввода-вывода. То есть у каждого сервера есть физическая карта ввода-вывода (на подобии классической «мезанины»), которая агрегирует на себе все типы трафика и позволяет нарезать много виртуальных адаптеров Fibre Channel, FCoE,Ethernet или даже iSCSI в любых комбинациях.
Например — у нас есть блейд, на который мы будем устанавливать ESXi. По дизайну нам нужно 4 интерфейса 10G Ethernet и 2 HBA карточки FC 8G. Мы заходим в UCS Manager и для конкретного сервера, или группы серверов нарезаем необходимую нам конфигурацию.
Максимальная пропускная способность на лезвие по всем протоколам — 40G (если не ошибаюсь).
Вторая удобная вещь это сервисные профили (Service Profile), которые представляют собой некий образ сервера, и содержат все его настройки, MAC и WWN адреса, настройки БИОС, настройки адаптеров и т.п.. Это дает простую переносимость настроек с одного сервера на другой.
Немного объясню на примере:
Есть у нас блейд с работающей на нем СУБД Oracle (к примеру). Реализована схемаBoot-from SAN и все данные лежат на LUN-ах СХД. В случае, если сервер выходит из строя, мы извлекаем его из шасси, ставим на его место другой сервер (при чем необязательно такой же конфигурации железа) и накатываем на него профиль старого сервера. После данной операции, новый сервер получит абсолютно все настройки старого сервера (включая WWN и MAC адреса) и сможет загрузиться без выполнения дополнительных действий (настройки зоннинга, маппинга LUN-ов на стороне СХД и пр.).
Таким образом, замена вышедшего из строя сервера займет минут 15…
Кроме быстрой замены профиля у нас появляются возможности клонирования и создания шаблонов сервисных профилей.
Представим другой сценарий:
У нас есть виртуальная инфраструктура из 15 однотипных серверов. Все сервисные профили созданы на основе шаблона. Щедрое руководство купило еще 8 серверов для расширения существующей инфраструктуры. Вместо долгой и нужной прошивки каждого сервера, настройки адаптеров, политик загрузки и т.п. мы выставляем каждому серверу актуальную версию прошивки, а потом в несколько кликов разворачиваем из шаблона 8 новых сервисных профилей и привязываем их на новые сервера. В результате новые сервера получают типичные для данного шаблона настройки и WWNMAC-адреса из пулов — вуаля!
И много других примеров можно привести, где данные фичи будут очень к стати, все зависит от вашей фантазии 😉
Итак, хватит хвалить Cisco UCS — пора немного и поругать :))
Из негативных моментов, blade-системы Cisco UCS, можно выделить ее неотесанность. Т.к. система не очень давно на рынке, по сравнению с конкурентами. При работе с ней складывается впечатление, что она пока что немного сыровата и имеют место быть мелкие и не очень глюки.
Хотя, коллеги, работающие с блейдами других вендоров, говорят что это вполне нормально и глюки есть у всех.
В оправдание данной ситуации могу сказать по собственному опыту, что за последние 2 года моего знакомства с Cisco UCS прогресс в этом плане есть немалый, как в плане функционала, так и в плане стабильности. Это значит, что работа над допиливанием софта и железа активно ведется.
Ну и напоследок хотелось бы упомянуть о том, что на основе блейдов Cisco UCSпостроены такие программно-аппаратные комплексы как Vblock от компании VCE,VSPEX от компании EMC и Flexpod от Cisco и NetApp.
Данные комплексы представляют собой готовые решения для построения облачной инфраструктуры и они заслуживают отдельной статьи. Постараюсь в будущем рассказать немного об их архитектуре и поделиться опытом внедрения, если будет интерес у читателей.
Все это очень поверхностно, и наверняка многие это знают, но в дебри залезать не хочу т.к. получится летопись на несколько мегабайт :))
Вообще, буду рад выслушать вопросы и замечания. Если что-то было не совсем понятно (или совсем непонятно) — постараюсь рассказать об этом более подробно.
з.ы. все фотки и рисунки из интернета.

